Connect
Databases, files, APIs and applications
PREDATA is a cloud tool to transform, clean, anonymize, enrich and export data before integrating it into Data Spaces.
Project funded by the Ministry for Digital Transformation and Public Function within the framework of the Recovery, Transformation and Resilience Plan - Funded by the European Union – NextGenerationEU.
File: TSI-100130-2024-0044 Beneficiary entity: Biuwer Analytics S.L.
Prepare your data for the collaborative future
Organizations that want to participate in Data Spaces face disparate, heterogeneous, incomplete or unreliable data. Before making them public or publishing them, they need to clean, normalize, anonymize information. sensitive, improve its quality and export it in interoperable formats.
A cloud platform for preparing datasets ready for Data Spaces
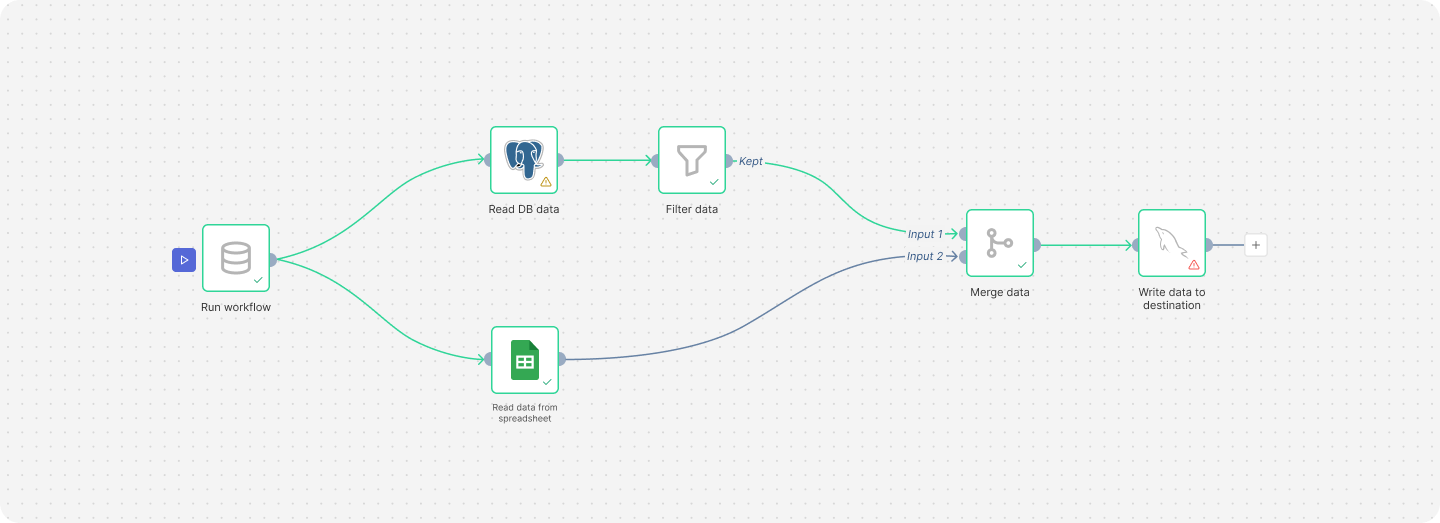
PREDATA allows you to build data workflows using an easy-to-use visual editor, combining source, transformation, and destination nodes. Processes can be executed manually, through automatic triggers, or by events.
Databases, files, APIs and applications
Cleaning, quality, merge, purging and normalization.
Anonymization, synthetic data generation and governance.
CSV, Excel, JSON, Parquet, APIs and destinations prepared for Data Spaces.
Design data processes without unnecessary technical complexity.
Databases, standard files, REST APIs and GraphQL.
Prepare sensitive data for safe use.
Create useful data for testing, innovation and sharing without exposing real information.
Detect errors, incomplete values, anomalies and homogenization problems.
Prepare datasets in formats compatible with Data Spaces ecosystems.
Discover how Predata can adapt to your data processes and structure. We show real examples applied to your sector.
Standards and interoperability
PREDATA is aligned with initiatives and standards such as Gaia-X, IDS and DSSC and allows preparing data in interoperable formats such as JSON-LD, CSV and Parquet, incorporating flexible connectors, APIs and anonymization and governance capabilities.
PREDATA is designed for companies and organizations that need to prepare data before connecting them to sector or federated data spaces.
Anonymization and homogenization of sensitive data.
Analytics data and sector dataset preparation.
Cleaning and normalization of sensor data.
Integration, quality and synthetic data.
Preparation of secure and interoperable data.
Quality improvement and standardization.
We are selecting organizations interested in trying PREDATA with real use cases for data preparation, anonymization, cleaning, transformation, and export for Data Spaces.
Quick answers about how Predata works in collaborative data ecosystems.
PREDATA is a cloud tool to prepare, transform, and refine data before integrating it into Data Spaces. It allows you to create visual workflows with input, transformation, and output nodes to automate processes such as cleaning, anonymization, quality improvement, synthetic data generation, and export.
PREDATA is used through a visual workflow-based interface. Users connect data sources, add transformation nodes, and define the final destination for prepared data. Processes can be executed manually or automated through triggers.
Yes. There is a free access plan with limited functionality and usage, for organizations interested in validating real data preparation scenarios, especially those aimed at Data Spaces.
PREDATA is designed as a scalable cloud platform. Capacity will depend on the plan, allocated infrastructure, workflow type, and data volume being processed, and can scale from simple cases to more advanced scenarios.
PREDATA is licensed under a SaaS model, based on usage subscription. Cost will depend on the number of active workflows and monthly processing time. Additional services will be available as add-ons for configuring advanced nodes and receiving personalized support.
No. PREDATA is not a Data Space, but rather a tool that helps prepare data so it can be better integrated into them. Its function is to act as a prior layer for treatment, quality, privacy, and interoperability.
PREDATA is designed to work with data from databases, files, APIs, and external applications. It can be used with common formats such as CSV, JSON, Parquet, or data accessible via REST and GraphQL APIs.
PREDATA helps solve common problems such as incomplete data, format errors, lack of standardization, sensitive information that needs to be anonymized, need for synthetic data generation, poor data quality, or preparation of datasets for export in interoperable formats.
PREDATA works with data in transit during workflow execution and with metadata necessary to manage users, workflows, nodes, and executions, but does not persistently store data as such. However, in each client's final configuration, specific policies for storage, retention, and security can be defined, as well as the use of a Data Lake and/or Data Warehouse managed by Biuwer.
Yes. PREDATA is designed to prepare data before integration with Data Spaces. It can facilitate the export of transformed, clean, and anonymized data in interoperable formats or via specific connectors depending on the case.
Join our community and start preparing your data for Data Spaces today.
Prefer to write to us?
sales@biuwer.comPrefer to talk?
(+34) 868 941 353Biuwer is an ENISA-certified technology startup based in Murcia, specialized in Business Intelligence and data analytics. With more than 15 years of experience, we transform R&D+i projects into market-ready solutions.
Learn more